
[Java] JPA가 뭐에요

Spoiler
JPA의 컨셉과 구조, 대략적인 동작 과정에 대해 설명한다.
JPA 란
Java Persistence API
The java ORM standard for storing, accessing, and managing java objects in a relational database
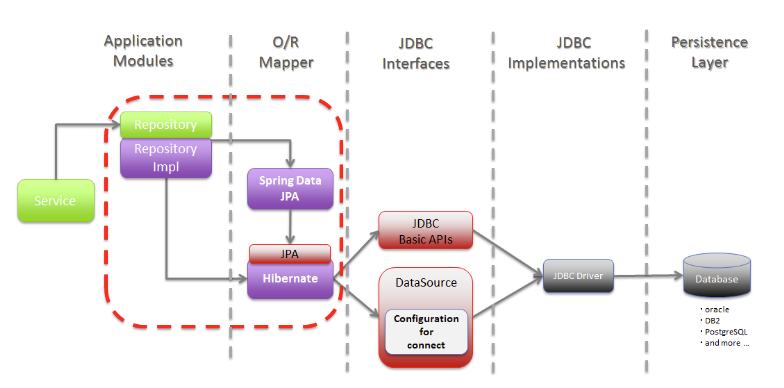
- Java에서 정의한 API이며, ORM 표준이자 스펙이다.
- 구현체가 아니기 때문에 자체로서 어떤 동작을 하지 않는다.
- 대표적인 구현체로 Hibernate 가 있으며 java의 객체와 DB 테이블을 매핑한다.
- 일부 JPA 구현체는 NoSQL DB도 지원한다(EclipseLink).
JDBC: Java DataBase Connectivity
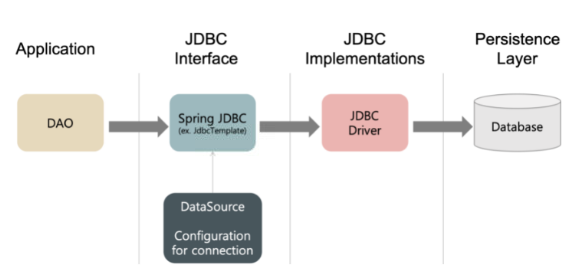
DB와 Java 앱 사이의 커넥션을 관리하고, 쿼리를 전달하기 위해 정의된 Java의 API. 거의 모든 Java 기반의 Data Access Layer에서 내부적으로 쓰고있다고 보면 된다. JPA 역시, 결국엔 JDBC를 통해 Persistence Layer에 접근한다.
ORM과 SQL Mapper의 차이
ORM (Object-Relational Mapping)
Object \(\leftrightarrow\) Relation(Tables)
- 객체와 테이블 데이터 사이의 패러다임 불일치를 해결해준다.
- 객체를 통해, 애플리케이션 코드 상에서 간접적으로 DB 데이터를 다루게 해준다.
- 개발자가 SQL을 직접 작성하지 않아도 SQL문을 자동으로 생성해준다.
- 대표적인 구현체로 Hibernate가 있다.
SQL Mapper
Repository의 메소드 \(\leftrightarrow\) SQL문
- 개발자는 xml 형태로 SQL을 직접 작성해야 한다.
- 작성한 SQL 문은 애플리케이션 repository의 메소드와 매핑된다.
- DBMS가 변경될 경우 애플리케이션 코드 또한 변경이 필요하다.
- 대표적인 구현체로 Mybatis, JdbcTemplate가 있다.
JPA의 장점
- 개발자는 JPA에게 SQL을 맡기고 비즈니스 로직에 집중할 수 있다.
- DB Vendor 종속성이 없기 때문에, 애플리케이션 소스코드의 변경 없이 DBMS를 변경 할 수 있다.
- 객체를 통해 쿼리를 작성할 수 있는 JPQL(Java Persistence Query Language)를 지원한다.
- 최적화(lazy loading, caching, write behind 등)로 인한 이점을 누릴 수 있다.
JPA에서의 영속성
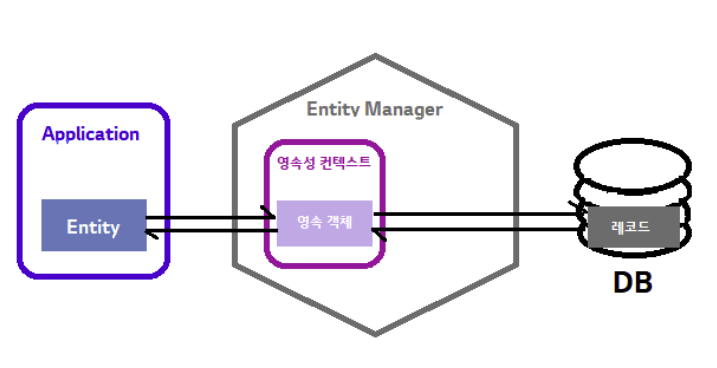
JPA는 영속성 구현을 위해 영속성 컨텍스트라는 것을 관리한다.
JPA의 Entity Manager가 활성화된 상태로, 트랜잭션(@Transactional 애너테이션이 달린 스코프) 안에서 Entity로 관리되는 class의 객체가 선언되어 있다고 가정하자.
이때, 이 객체의 영속성 컨텍스트가 유지되며, 이 상태에서 멤버변수의 값을 변경하면 트랜잭션이 끝나는 시점에 해당 객체가 매핑된 테이블 레코드의 데이터가 업데이트 된다.소스코드 상에서 update 메서드를 호출하지 않아도 업데이트는 일어나며, 이를 Dirty check 라고 한다.
- Spring Data JPA를 사용하면, 기본적으로 Entity Manager는 활성화된다.
- 영속성 컨텍스트는 엔터티를 담고있는 집합이며, 직접 접근은 불가능하다(Entity Manager를 통해서만 접근).
JPA의 동작과정
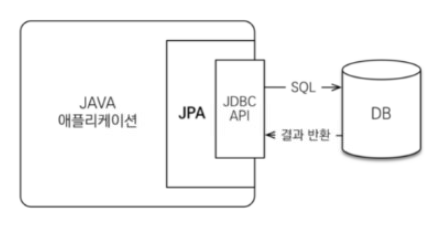
- 백엔드 로직에서 JPA의 API 메소드(ex.
persist) 호출 - JPA의 구현체(ex. Hibernate)가 쿼리를 생성
- 생성된 쿼리가 JDBC가 관리하는 DB 커넥션을 통해 DB로 전달
예시를 통해 자세히 살펴보자.
insert
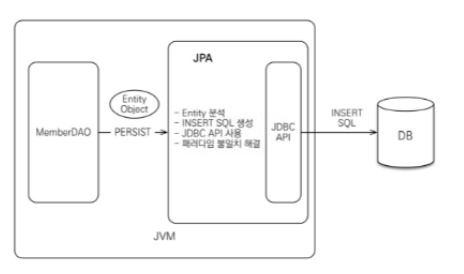
Member Entity의 persist 메서드가 호출되면:
- Member 객체를 검사
- JPA 구현체에 의한 INSERT SQL 생성
- 생성된 쿼리를 JDBC API 호출을 통해 DB로 전달
find
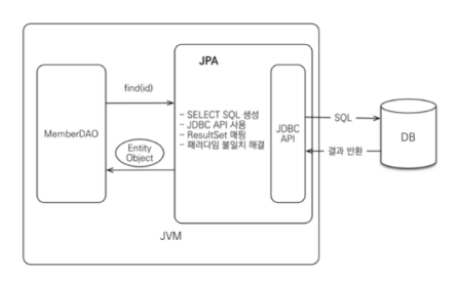
MemberRepository 의 find 메소드가 호출되면:
- 영속성 컨텍스트에 해당 Entity 객체가 이미 존재하는지 조회(in memory)
- 존재할 경우, 해당 Entity 리턴
- 존재하지 않을 경우, JPA 구현체에 의한 SELECT 쿼리 생성
- 생성된 쿼리를 JDBC API 호출을 통해 전달
- 조회된 데이터를 Member 객체의 필드에 담아 반환
JPA가 알아서 해주는 최적화
JPA 또한 미들웨어이며, 미들웨어가 성능 개선을 위해서 흔히 사용하는 방식 중 아래 두 가지가 있다.
Buffering을 통한 overhead 최소화Caching을 통한 query 성능 향상
무슨 얘긴지 간단히 살펴보자.
Buffering
쓰기 지연(transactional write-begind)
insert
public void jpaExampleService() {
transaction.begin();
jpaRepository.save(entityA);
jpaRepository.save(entityB);
// 여기까지는 entityA, entityB와 관련된 테이블 데이터에 변경이 없다.
transaction.commit(); // DB connection이 이때 할당되고 테이블 데이터가 변경된다.
}
update
public void jpaExampleService() {
transaction.begin();
jpaRepository.update(entityA);
jpaRepository.delete(entityB);
// 여기까지는 entityA, entityB와 관련된 DB 테이블 데이터에 변경이 없다.
doBusiness(); // 비즈니스 로직을 수행하는 동안 DB lock이 발생하지 않는다.
transaction.commit(); // DB lock을 이때 획득. 변경사항이 테이블 데이터에 반영된다.
}
Caching
이미 조회한 적이 있는 최근의 데이터라면, DB 쿼리는 생성/전달하지 않는다.
public void jpaExampleService() {
String entityId= "sameId";
Entity instanceA, instanceB;
instanceA= jpaRepository.find(Entity.class, entityId); // entity 조회
instanceB= jpaRepository.find(Entity.class, entityId); // cached retrieval
boolean isInstanceSame= instanceA == instanceB; // true
}
Lazy loading (지연 로딩)
데이터가 실제로 사용되는 시점까지 조회를 미룬다.
Team : Member = 1 : N 관계라고 하자.
Member 엔터티는 멤버변수로 본인이 속한 팀에 해당하는 Team 엔터티를 가지고 있다.
public void jpaExampleService() {
Member member = memberRepository.find(memberId);
// SELECT * FROM member WHERE member_id = memberId;
Team team = member.getTeam();
// No SQL executed here
String teamName = team.getName();
// SELECT * FROM team WHERE team_id = member.teamId;
}
위의 예시에서는 쿼리 전달이 두 번 일어난다.
그런데 Member 데이터를 참조할 때 대부분 Team 데이터도 함께 참조되는 상황이라면, Eager Loading을 고려해볼 수 있다.
Eager loading (즉시 로딩)
: 연관된 객체들을 모두 미리 조회하는 전략
public void jpaExampleService() {
Member member = memberRepository.find(memberId);
// SELECT *
// FROM member WHERE member_id = memberId
// JOIN team WHERE member.team.team_id = team.team_id;
Team team = member.getTeam();
// No SQL executed here
String teamName = team.getName();
// No SQL executed here
}
JPA 구현체의 기본 설정은 Lazy Loading 이다.
Member 엔티티와 Team 엔티티가 함께 참조되는 빈도수를 조사하고, 대부분의 경우 함께 참조되는 경우에 한해 Eager Logding 을 적용하는 것이 권장된다.
정리하며. Spring Data JPA
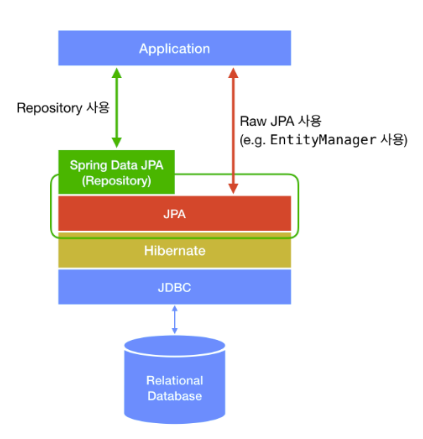
JPA와 Spring Data JPA는 엄연히 다르다. (연두색과 빨간색)
Spring Data JPA는 JPA 구현체(ex. Hibernate)를 쉽게 사용하기 위해 Spring framework에서 제공하는 일종의 프레임워크이며, JPA 구현체 및 연결되는 DB를 application 설정으로 쉽게 교체할 수 있게 해준다.
- Java의 Redis 클라이언트가 Jdis에서 Lettuce로 대세가 바뀔 때 Spring Data Redis를 사용하고 있었다면 손쉽게 교체가 가능했다.
- Spring Data JPA, Spring Data mongoDB, Spring Data Redis등 Spring Data 프로젝트의 하위 프로젝트들은 동일한 인터페이스(findAll, save 등등 ..)를 구현하기 때문에, DB를 교체해도 Java 소스코드를 수정할 필요가 없다.

Leave a comment